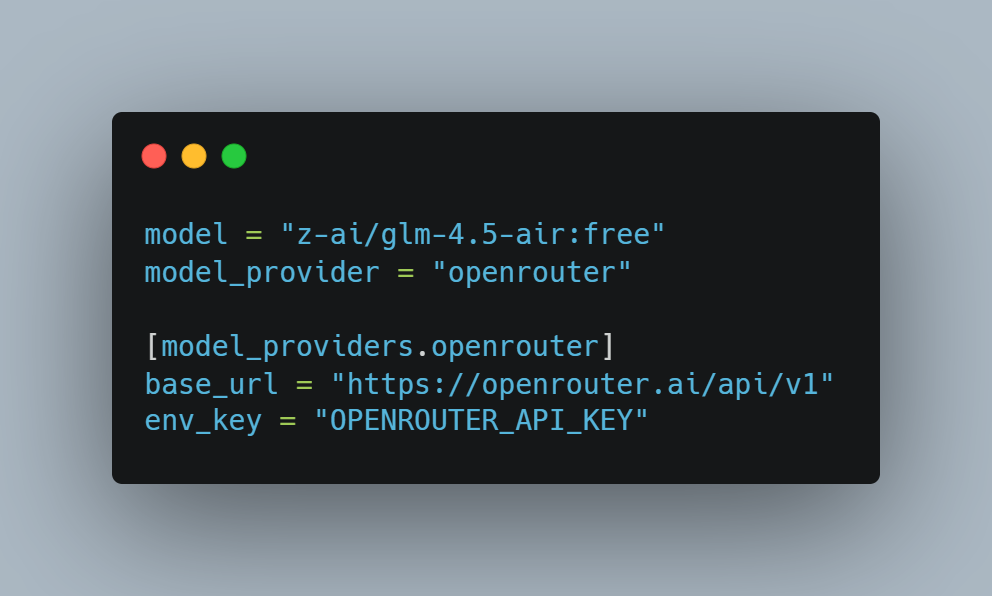
Quick setup: After installing Codex CLI, it automatically creates a default configuration file under your user directory: Windows: Linux / macOS / WSL: Then you just edit that file,→ add the [model_providers.openrouter] section,→ and update the existing model and model_provider lines, like this: Then run: Views: 1135

AI / PHP
Symfony’s Experimental AI Store: A Deep Dive into InMemoryStore
Symfony is steadily evolving into a modern AI-enabled framework—and one of its most exciting experimental additions is the symfony/ai-store component. This new package lays the foundation for semantic search, context injection, and Retrieval-Augmented Generation (RAG) workflows directly inside PHP applications. What Is Symfony AI Store? The AI Store component is a low-level abstraction for managing vector stores. In simpler terms, it helps store documents as embeddings (numerical vectors) and retrieve them later using similarity search. This is crucial in RAG scenarios, where an AI agent dynamically pulls relevant facts from a custom knowledge base before answering user queries. This component […]

AI
My First Successful Fine-Tuning of an LLM on Custom Symfony + Chameleon Knowledge
After several trials and experiments, I’ve finally completed my first successful fine-tuning of a LLaMA-based model using my own real-world internal IT documentation. This project fine-tunes a 3B parameter model to understand and respond to Symfony command usage, Chameleon CMS workflows, and developer issues like rsync errors or Xdebug debugging failures. The result is now publicly available on Hugging Face: kzorluoglu/chameleon-helper Setup Overview I used the excellent Unsloth Synthetic Data Kit and trained the model on a curated dataset of 32 instruction-based Q&A pairs, written in natural German developer language. Instead of the usual instruction/input/output JSON format, I opted for […]

AI
OG video from talk by @ilyasut at the Neural Information Processing Systems (December-24, Vancouver) – DE, EN, TR Subtitle/Untertitel/Altyazı
Original (English): [00:00.000 –> 00:15.860]I want to thank the organizers for choosing a paper for this award. It was very nice. And I also want to thank my incredible co-authors and collaborators, Oriol Vinyals and Quoc Le, who stood right before you a moment ago. And what you have here is an image, a screenshot, from a similar talk 10 years ago at NeurIPS in 2014 in Montreal. It was a much more innocent time. [00:15.860 –> 00:35.980]Here we are, shown in the photos. This is the before. Here’s the after, by the way. And now we’ve got my experienced, […]

AI / Development / PHP
New Chameleon AI Model: Chameleon-Code_Explation_Gemma29b-v2
I am excited to introduce my new Chameleon AI model – Chameleon-Code_Explation_Gemma29b-v2! This model has been specifically developed to understand and explain the classes of the Chameleon CMS system and is optimized for efficient inference using 4-bit quantization. This makes the use of the model even more resource-efficient and faster. What is the Chameleon-Code_Explation_Gemma29b-v2 Model? Chameleon-Code_Explation_Gemma29b-v2 is a fine-tuned version of the Unsloth Gemma model and is based on a transformer-based language model. It has been trained to explain the structure and components of the Chameleon CMS system. The Chameleon CMS is a combination of shop software and content management […]

AI / Development / PHP
Accelerating Model Training with Unsloth: My Chameleon CMS AI Journey
In the rapidly evolving world of AI, staying ahead with cutting-edge tools and techniques is vital. Recently, I completed a successful model training session with Unsloth, a library designed for faster, more efficient model fine-tuning. My goal was to enhance the understanding and generation of PHP class explanations within the Chameleon CMS framework using the Gemma-2-9b model. Here’s a step-by-step recount of how I leveraged Unsloth to achieve fast, accurate results while keeping memory usage optimal Setting Up Unsloth for Model Fine-Tuning I began by installing the necessary packages for Unsloth and Flash Attention 2, a library crucial for softcapping […]
AI / Development / Linux / PHP / Server / Ubuntu
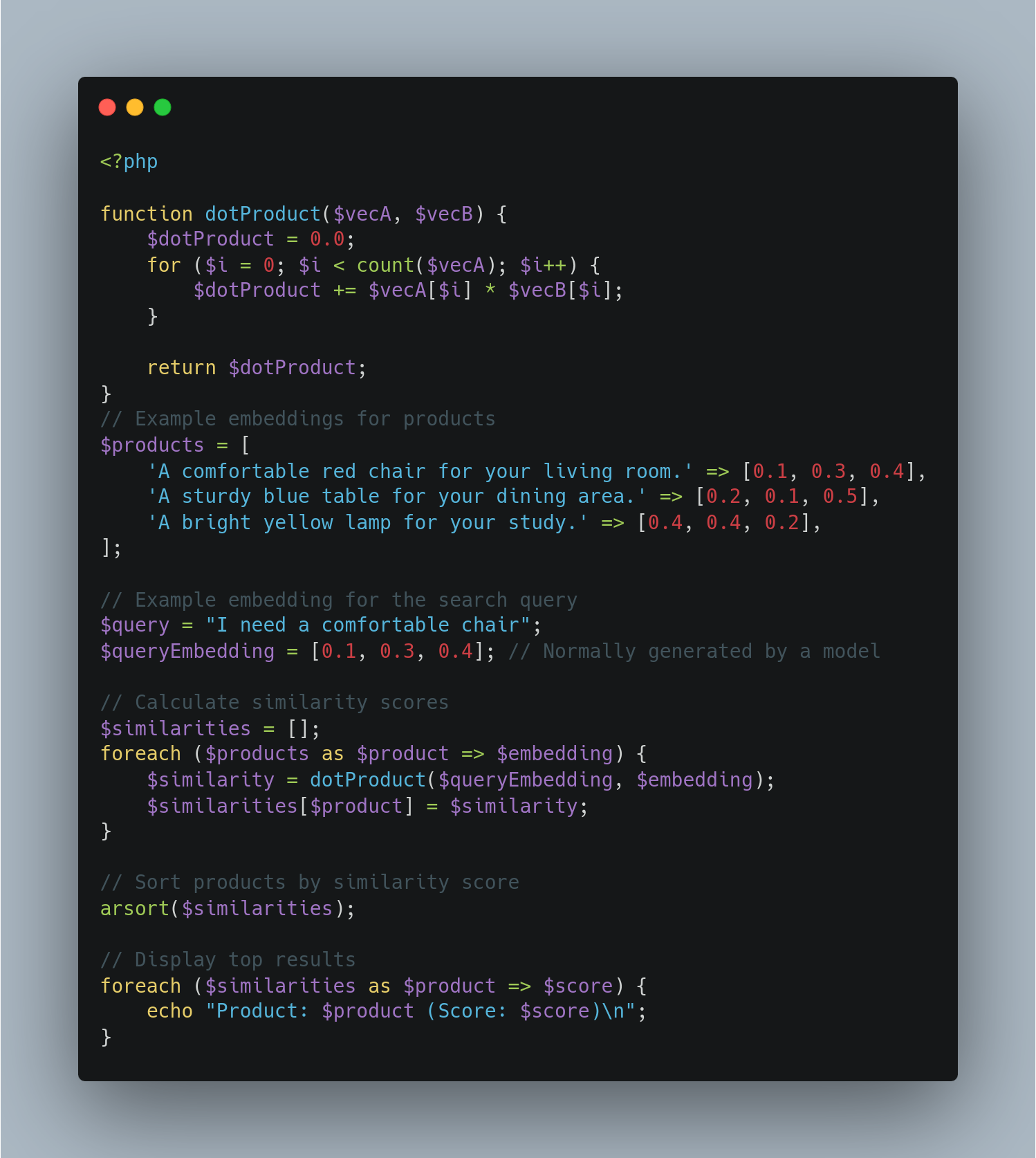
Building a Product Search System with Sentence Embeddings and Similarity Scoring
We will explore how to build a product search system that leverages sentence embeddings and similartiy scoring to improve search relevance. For this projekt, we need a lightweight model from “sentence-tansformers” library. Wyh: Because we need per Product Vector Space, that must be fast and stabil. I Founded this “all-MiniLM-L6-v2” model, is small, efficient and maps sentences to 384-dimensional dense vector space, making it suitable for tasks like semantic search. Let’s Start, Step 1: Setting Up the Envrioment: First, install the necessary library: Then, import the required modules and load the model: Step 2: Generation Embeddings: We will generate embeddings […]
AI / Development / PHP
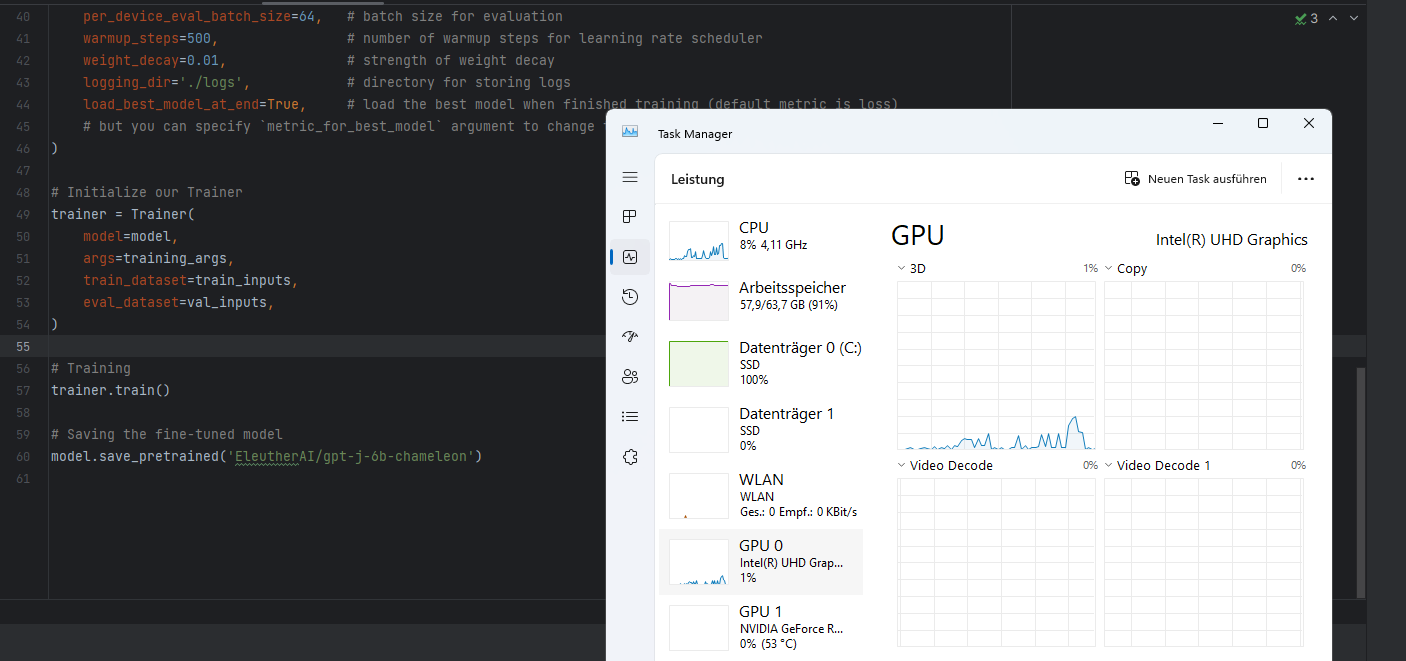
AI Model Trainer with EleutherAI/gpt-j-6b for Chameleon Shop Codes
The Trainer use actually the best chatgpt alternative model on huggingface. Here is the Training notice from Original Source: This model was trained for 402 billion tokens over 383,500 steps on TPU v3-256 pod. It was trained as an autoregressive language model, using cross-entropy loss to maximize the likelihood of predicting the next token correctly. https://huggingface.co/EleutherAI/gpt-j-6b#training-procedure Dataset Links: https://d8devs.com/chameleon-base-and-chameleon-shop-datasets-20230530-1918/ Views: 26